深入 Hadoop 大數據分析:請先由叢集中開始吧!
深入 Hadoop 大數據分析:請先由叢集中開始吧!
近年來大數據 (Big Data) 一詞不斷在媒體上出現,2012 年紐約時報更指出「大數據」時代已經降臨。大數據時代的來臨為不少公司,組織和政府機構帶來無盡的機遇。大數據看似與一般市民邈若河山,但與我們日常生活卻息息相關,近至超市的貨物排位,遠至人工智能,背後都有使用大數據分析。
而 Hadoop 更是大數據分析中的佼佼者,他是 Apache 軟件基金會基於 Google 提出的 MapReduce 軟體架構所研發的大數據分析軟體。由於其免費開放原始碼,並以 Java 編寫,使得其快速發展在大數據分析中佔一重要席位。要構成一個 Hadoop 叢集並不需要高昂的硬件,少至數部 Raspberry Pi 便行。
Hadoop 主要分為 HDFS 和 MapReduce 兩大部分。HDFS 可細分為 NameNode 和 DataNode。MapReduce 則由 JobTracker 和 TaskTracker 兩部分組成,以下講解每部分是負責什麼功能︰
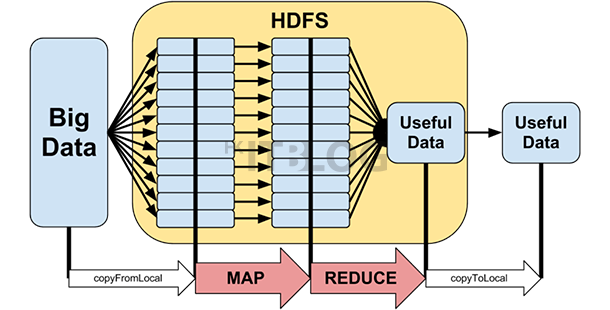
HDFS︰全寫為 Hadoop Distributed File System。它會將一個大容量的文件平均分拆,再分散儲存在不同的 DataNode 之中。HDFS 預設會將一個文件備份三份分散儲存,最多為五百一十二份,以避免一個 DataNode 損壞影響整個運算過程,提供一個高可用性的儲存環境。使用者可透過一系列 Shell 命令管理 HDFS。
NameNode︰為整個 Hadoop 叢集的大腦,它提供了整個 HDFS 的文件目錄信息,但不會儲存實質的檔案,通常會身兼 JobTracker,管理各個 DataNode。叢集一般會配置多一個 Secondary NameNode,此機在正常情況下不會參與在數據分析的過程,他只會在後台備份 NameNode 的數據。如 Namenode 不幸發生故障,Secondary NameNode 的數據可幫助技術人員更快捷重建 NameNode。當使用者想存儲 HDFS 數據時,DataNode 會先詢間 NameNode,以獲得數據放置在各 DataNode 的位置。
DataNode︰負責儲存實質數據,一份檔案會分散儲存在多個 DataNode,以確保安全性。通常身兼 TaskTracker 一職。
MapReduce︰如名所是,分為 Map 和 Reduce 兩部分。Map 是將數據分析過程分拆成無數小組件,以分配給各 TaskTracker 進行並行運算。Reduce 再將各個 TaskTracker 運算後得到的資料合併並輸出成最終結果。
JobTracker:在整個 Hadoop 叢集中只有一個 JobTracker,負責將 Map 和 Reduce 程序分配給 TaskTracker,為整個數據分析過程的指揮家。
TaskTracker:負責執行實質 MapReduce 程序。每個 TaskTracker 都會預設一些 slots,slots 為 TaskTracker 最多可接受的任務數目。當系統進行 MapReduce 程序時,JobTracker 會優先選擇身兼 DataNode 及有閒置 slots 的 TaskTracker。
瀏覽相關文章
深入 Hadoop 大數據分析:請先由叢集中開始吧!
深入 Hadoop 大數據分析:初探網絡環境與設定
深入 Hadoop 安裝與設定:1.X 跟 2.X 版本最大分別是…?
深入 Hadoop 安裝與設定:SSH 私有鑰匙設定與安裝
深入 Hadoop 安裝與設定:SSH 私有鑰匙設定與安裝(1)
Wordcount 測試實作:教你以 Hadoop 進行簡單文字分析!